Delta means change.
As I mentioned in my last blog there are a few modern ways to do “change control”. This is when you control the change of your data on your destination (or target) tables. Today we are going to talk about the latest and greatest, which is Delta Lake (well, besides Delta Live Tables, which we will get to next time).
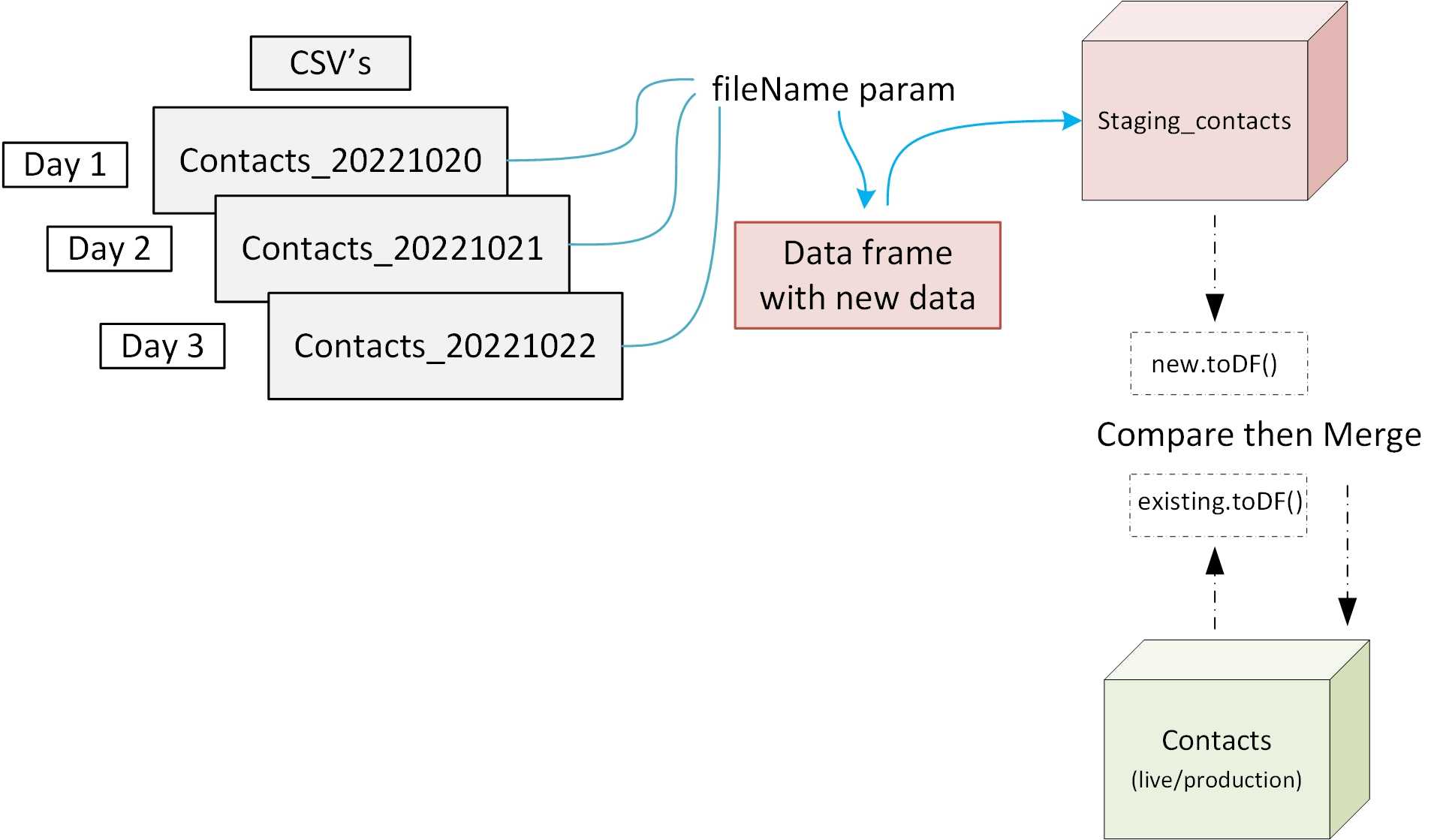
I have built a demonstration and YouTube video that is based on a Notebook that you can find on my GitHub page. It has the Databricks notebook and the contact csv demo files here

The Delta operation explained
It is very much like a normal SQL Merge statement, in fact it will built around this concept. In the Notebook you will see that we use a Merge operation. This is set on a join criteria, a way in which the engine can compare the source data to the target data and match on a Primary key as it were.
In this case every “contact” (a person), has a “constituentId” number, its like their ID number.
I will explain the merge concept in detail
dfex = data frame for the existing live table (contacts)
dfnew = data frame that holds the incremental load (and will already be written to the staging_contacts table)
dfex.alias('dfex').merge(dfnew.alias('dfnew'), 'dfex.ConstituentID = dfnew.ConstituentID')
- the part before the .merge is the target table
- within the () you have the first part, the source (this is the data coming in from the incremental file)
- then the join criteria ConstituentID = ConstituentID